Index of Coincidence
Summary §
The index of coincidence is a measure of how similar a frequency distribution is to the uniform distribution. The I.C. of a piece of text does not change if the text is enciphered with a substitution cipher. It is defined as:
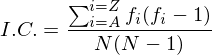
where fi is the count of letter i (where i = A,B,...,Z) in the ciphertext, and N is the total number of letters in the ciphertext. To calculate the I.C. for a specific piece of text, head down to the javascript implementation.
A Javascript I.C. Calculator §
Introduction §
Counting the frequency of letters is an important part of the cryptanalysis of most classical ciphers. If we compare the frequencies of text enciphered with a substitution cipher and another piece of text enciphered with the Vigenere cipher, we see that the frequency distribution is much flatter for the Vigenere text. The substitution cipher frequency distribution looks much 'spikier' or 'rougher' than the Vigenere distribution (see these images below for an example). The index of coincidence is a way of turning our intuitions about spikiness or roughness of the frequencies into a number. If the frequencies are very spiky, we get a higher number, if the frequencies are all roughly the same we get a lower number.
If we have a piece of english text roughly 1000 characters in length, we can be reasonably sure that the letter 'E' will appear around 127 times. As the text gets longer, we expect the proportion to remain roughly the same, in other words the probability of finding an 'E' is around 12.7%, or
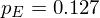
We also have the condition that all of the probabilities must add to 1, i.e.
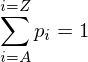
A Measure of Roughness §
If all of the letters occurred with the same frequency, the probability for each letter would have to be 1/26, or around 0.0385. This would give a completely flat distribution. The amount that the probability of 'E', pE differs from 1/26 is pE - (1/26) = 0.127 - 0.0385 = 0.0885. If we wanted to calculate the amount that all the letter probabilities differed from (1/26), we could calculate the sum of the difference for each letter. Unfortunately some letters would have a positive difference, and some would have a negative difference. This would mean the total difference would cancel out, leaving us with a sum of 0 every time.
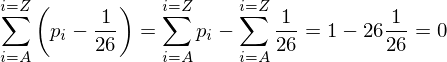
To circumvent this problem, we could square the difference (pi - (1/26)), ensuring the result is always positive. In this way we could calculate a measure of roughness, we will call it M.R.
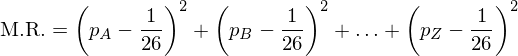
or more succinctly
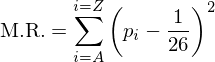
Expanding out, we get
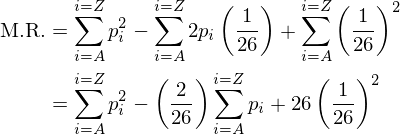
but we know the sum of pi over all the letters is 1, so this further simplifies to
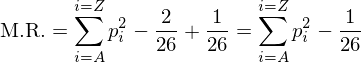
If we calculate the sum of squares of each letter probability using the probabilities from e.g. wikipedia, we get a value of 0.066. If all our probabilities were (1/26), we get 0.038. As a result, our M.R. will give a number of 0.066-0.038 = 0.028 if the frequency distribution is similar to English, and a value of 0.038-0.038 = 0 if the frequency distribution is flat.
Approximating M.R. §
What does our formula really mean? If
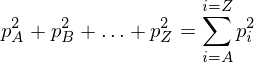
Using this information, we can approximate the calculation of M.R. without actually calculating pi for each letter. If there are 10 A's, there are 10 possible A's to pick. If we want to pick a second A, there are 9 left to choose from. This means there are 10*9 different ways to choose an A. In this count, each pair has been counted twice since the same pair can be obtained in 2 orders. Our final number of ways is (1/2)*10*9. If we have a cipher text with fA occurrences of the letter A, the number of pairs of A's that can be formed is fA(fA-1)/2. In the same way, the number of ways to choose 2 B's is fB(fB-1)/2. If we want to know how many ways to choose 2 of the same letter, irrespective of the actual letter, we could calculate it as follows:
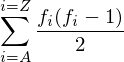
If there are N letters in our ciphertext, there are N(N-1)/2 total ways of choosing 2 letters. The chance of 2 letters being the same is the total number of ways of choosing 2 of the same letter, divided by the total number of ways of choosing 2 letters. This is
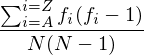
Since this represents the chance that 2 letters are alike, it is called the Index of Coincidence, or I.C.
An Example §
We will compare two ciphertexts, one which has been enciphered with the simple substitution cipher, and another that has been enciphered with the Vigenere cipher with a period of 6. The substitution cipher:
wmzfxtdhzfngfwxwnwxjevxdmzoxfkvxdmzowmkwmkfgzzexenfzpjotkebmneloz lfjpbzkofxwvjefxfwfjpfngfwxwnwxeszyzobdhkxewzawvmkokvwzopjoklxppz ozewvxdmzowzawvmkokvwzoxwlxppzofpojtvkzfkovxdmzoxewmkwwmzvxdmzokh dmkgzwxfejwfxtdhbwmzkhdmkgzwfmxpwzlxwxfvjtdhzwzhbrntghzl
The Vigenere Example:
vptzmdrttzysubxaykkwcjmgjmgpwreqeoiivppalrujtlrzpchljftupucywvsyi uuwufirtaxagfpaxzxjqnhbfjvqibxzpotciiaxahmevmmagyczpjxvtndyeuknul vvpbrptygzilbkeppyetvmgpxuknulvjhzdtgrgapygzrptymevppaxygkxwlvtia wlrdmipweqbhpqgngioirnxwhfvvawpjkglxamjewbwpvvmafnlojalh
If we look at the frequency distributions of both of these ciphertexts, it seems the Vigenere ciphertext is flatter than the substitution cipher.
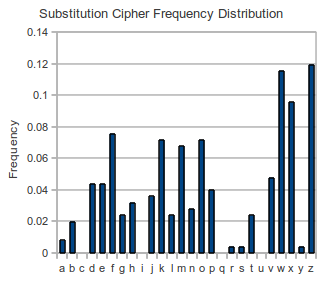
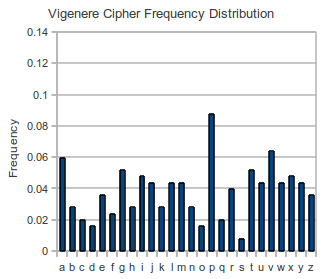
If we calculate the I.C. of these two ciphertexts, we get:
| Cipher | I.C. |
|---|---|
| Substitution | 0.066 |
| Vigenere | 0.042 |
The I.C. is much closer to what we expect for English text for the substitution cipher. This means we can differentiate between ciphers easily using only the ciphertext.
Relation to Chi-squared statistic §
The Chi-squared statistic compares two different probability distributions, whereas the I.C. compares one probability distribution to the uniform distribution. The measure of roughness we derived above (the M.R.) is related to the Index of Coincidence in the following way:
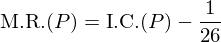
where P is the frequency distribution pA,pB... etc. The Chi-squared statistic is also related to M.R.,

where U is the uniform distribution pA=pB=...=1/26.
comments powered by DisqusContents
Further reading
We recommend these books if you're interested in finding out more.


")