Cryptanalysis of the Hill Cipher
For a recap of how the Hill cipher works, see here
2 by 2 Case §
Because the Hill cipher is linear, we only need to find 2 bigram correspondences to determine the key matrix. For example, if we knew that 'th' was encrypted to 'gk' and 'er' was encrypted to 'bd', we could solve a set of simultaneous equations and find the encryption key matrix. We will capitalise on this fact to break the cipher.
The method we introduce here will depend on knowing some of the words in the message. Imagine we have a ciphertext:
fupcmtgzkyukbqfjhuktzkkixtta
and we know that "of the" occurs somewhere in the message. This means one of the following cases is correct (remember the Hill cipher enciphers pairs of characters):
fu pc mt gz ky uk bq fj hu kt zk ki xt ta ----------------------------------------- of th e. .. .. .. .. .. .. .. .. .. .. .. .o ft he .. .. .. .. .. .. .. .. .. .. .. .. of th e. .. .. .. .. .. .. .. .. .. .. .. .o ft he .. .. .. .. .. .. .. .. .. .. .. .. of th e. .. .. .. .. .. .. .. .. .. .. .. .o ft he .. .. .. .. .. .. .. .. .. ...
and so forth. If the second line were correct, we would have the following: PC -> FT i.e. the letters PC are deciphered to FT, and MT -> HE. We can now set up an equation (replacing A with 0, B with 1, O with 14 etc.) which captures this information:
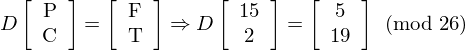
as well as the following equation:
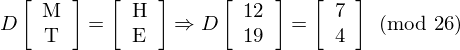
And we want to determine the matrix D which is the decryption key. We first combine the two equations above into one equation:
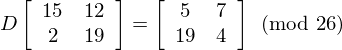
Now we can rearrange the equation to find the numbers we want:
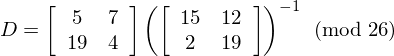
Now we need to invert a matrix (mod 26). The important things to know are inverses (mod m), determinants of matrices, and matrix adjugates.
Let P be the matrix we want to invert. Let d be the determinant of P. We wish to find P-1 (the inverse of P), such that P × P-1 = I (mod 26), where I is the identity matrix. The following formula tells us how to find P-1 given P:
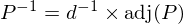
where d × d-1 = 1(mod 26), and adj(P) is the adjugate matrix of P. The determinant of the matrix we are inverting is ac - bd (mod 26) = 15*19 - 12*2 = 261 = 1 (mod 26). We also need to find the inverse of the determinant (1), which luckily in this case is 1 because 1 is its own inverse. The adjugate matrix is the following:
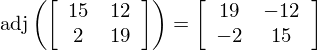
Now we can calculate the inverse:
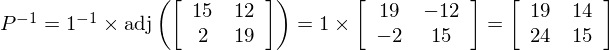
Now we need to go back up to our earlier equation to determine D. We have
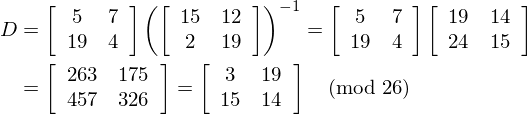
So now we have our decryption key! BUT, if we try to decrypt our sentence with it, we get:
frfthezyssqyvfetlvbafvaconfz
which is obviously not the correct answer! So what went wrong? It means one of our initial assumptions was wrong, the assumption being that our crib 'of the' began at the second position. To determine the actual key we need to try dragging 'of the' across each position until we get english at the output. If we had used an offset of 18, matching KT -> FT and ZK -> HE and repeated the procedure above we would get the matrix:

Now when we try to decrypt our ciphertext, we get:
defendtheeastwallofthecastle
Which is just what we wanted. The technique we have used here is called 'crib dragging', which can be very tiresome if performed by hand. It is much easier to write a computer program to do it for you.
Generalising to ciphertext only §
If we don't have a crib, we have to make a few changes. Instead of dragging a known 5-letter string along the ciphertext, we can drag a set of likely quadgrams. For example the most common quadgram in English is 'THAT'. So we make 'THAT' our crib, and perform the procedure above for all the different start positions. Then we try the second most common quadgram 'THER'. We keep trying these until we get a decrypted sentence that looks like english. This is the method used in the python implementation below.
Python Implementation of 2x2 Hill cracker §
This will be coming soon when I get around to it.
3 by 3 Case §
This is done almost identically to the 2 by 2 case. Instead of 5 letters though, we need 11 consecutive letters for the crib. A ciphertext only version of the 3 by 3 case is impractical.
comments powered by Disqus