Yet Another K-Means Tutorial
The purpose of K-means is to identify groups, or clusters of data points in a multidimensional space. The number K in K-means is the number of clusters to create. Initial cluster means are usually chosen at random.
Algorithm Description §
K-means is usually implemented as an iterative procedure in which each iteration involves two successive steps. The first step is to assign each of the data points to a cluster. The second step is to modify the cluster means so that they become the mean of all the points assigned to that cluster. The 'quality' of the current assignment is given by the following distortion measure:
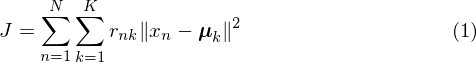
where 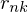 is a set of binary indicator variables such that
is a set of binary indicator variables such that 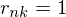 if
if 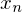 is on cluster
is on cluster 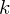 , and
, and 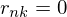 otherwise.
otherwise. 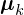 is the mean of the kth cluster, is the nth data sample. This distortion measure can be thought of as computing the variance of each of the clusters separately, then adding the variances for each cluster to get a single number. If the distortion is low it means the clustering is good. Generally you would run K-Means several times with different random initialisations and choose the clustering with the lowest distortion.
is the mean of the kth cluster, is the nth data sample. This distortion measure can be thought of as computing the variance of each of the clusters separately, then adding the variances for each cluster to get a single number. If the distortion is low it means the clustering is good. Generally you would run K-Means several times with different random initialisations and choose the clustering with the lowest distortion.
To perform K-means:
Initialisation: pick K of the data points to be the initial means.
- go over each data point and assign it to one of the means based on which is closest. E.g. if datapoint xn is closest to the second mean, assign it to that mean.
- Recompute each of the means as the average of all the points assigned to the mean.
In step 1 above, we need to know the distance between every datapoint and each of the means. This is done using standard euclidean distance, which is defined for spaces with arbitrary numbers of dimensions.
The two phases of reassigning data points to clusters and recomputing the cluster means are repeated in turn until there is no further
change in the assignments. Convergence of the k-means algorithm is guaranteed since the distortion measure is reduced after
each iteration, however it will not necessarily arrive at a global minimum of 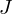 , it may simply arrive at a local minimum.
, it may simply arrive at a local minimum.
One of the limitations of the K-Means algorithm is that it can't figure out the number of clusters on its own, it has to be specified beforehand. When we start looking at a new set of data, K-Means would typically be one of the first things we use to understand the data better by identifying clusters. Since we don't know anything about the data, we just have to pick K points at random and use them as the initial cluster centers. K-means will then move the cluster centers around to better represent the data.
Here is a pretty animation showing how K-Means converges to the correct result given an arbitrary set of starting means, slowly refining them after each iteration.

In general K-Means doesn't work very well in high dimensional spaces or if the number of clusters required is very high (hundreds or thousands of clusters). With low numbers of clusters it is ok to run K-Means several times and pick the best clustering (based on the distortion measure J defined above), however even this doesn't work very well with lots of clusters, it is better to use the LBG algorithm.
The LBG Algorithm §
The LBG algorithm was introduced by Linde, Buzo and Gray in 1980. It starts with 2 clusters (run K-Means with 2 clusters until convergence), then the variance of each cluster is determined. The cluster that has the highest variance is split into 2 distinct clusters (for a total of 3 clusters). K-means is again run until convergence (with 3 clusters now). The algorithm then repeats until all clusters have been found. This will generally give you much a much better clustering than starting K-Means with K clusters at the start. Instead of adding 1 cluster at a time, you can also do binary splitting, where every cluster is split.
To split a cluster, just add a small noise vector to it and use the original clusters along with the slightly perturbed cluster as the initialisation for the next round of K-Means.
comments powered by Disqus